
DevOps Industry Updates #27: Hiatus Edition
Welcome back! Since the last issue, there has been a major development in my personal life. I inherited a new, highly-complex distributed system that’s under active development and needs constant attention. In other words, I became a Dad! To make sure I can dedicate the time needed to be the best co-parent possible, I am pausing DevOps Industry Updates for a little while. Stay tuned though, I will be back, and with more original content!
🔥 Top Cream
This issue’s top 5 stories:
- Reasons why bugs might feel “impossible”
- Sloth
- Navigating the 8 fallacies of distributed computing
- Zero downtime Postgres migration, done right
- Ness
🌎 Society
- Sole Black VMware principal engineer aims to diversify tech: VMware’s only Black principal engineer talks about his rise in the cloud-native world, how to bring in a new generation of minorities and the future of technology.

-
Microsoft announces Windows 11, with a new design, Start menu, and more: the big focus for Windows 11 is a simplification of the Windows user interface, a new Windows store, and improvements to performance and multitasking. Windows 11 will also include support for running Android apps for the first time.
-
Microsoft reaches a $2 trillion market cap: the tech giant is only the second publicly traded American company, behind Apple, to reach such a valuation. Oil company Saudi Aramco, which went public in 2019, has also previously passed that mark, though its market cap on Tuesday was $1.88 trillion.

-
2021 DevOps Trends – What We Learned From 450 Engineering Teams: Humanitec has collected a lot of data from engineering teams about their DevOps setup. Their analysis provides insights into the tooling most teams use, how they approach application configuration management and infrastructure configuration management, which DevOps metrics they measure and what we can learn from these metrics.
-
2021 SRE Report: Catchpoint’s annual report analyzed survey responses from over 300 site reliability engineers globally across a range of industries and company sizes. It reveals a wide range of fascinating insights and concludes with an actionable path for SREs to consistently deliver customer value.
📟 DevOps

-
Announcing HashiCorp Terraform 1.0 General Availability: Terraform 1.0 marks a major milestone for interoperability, ease of upgrades, and maintenance for your automation workflows.
-
Practical Guide to SRE: Incident Severity Levels: incident severity levels are a measurement of the impact an incident has on the business. Classifying the severity of an issue is critical to decide how quickly and efficiently problems get resolved.
-
Announcing Consul 1.10 GA: adds new features such as transparent proxy for service mesh, support for xDS v3, streaming, and observability enhancements.
-
Zero downtime Postgres migration, done right: a step by step guide to migrate your Postgres databases in production environments with zero downtime.
-
6 troubleshooting skills for Ansible playbooks: here are six ways you can check for problems when running Ansible playbooks.
-
Keeping up with Docker Official Images: we use Docker Official Images as the base images for several of our services. It’s a popular choice, and there are good reasons for this. A dedicated team reviews them at Docker and gets actively maintained by experts from their respective communities, including the security community.
🛠️ DevOps Tools
-
The Book of Secret Knowledge: a collection of inspiring lists, manuals, cheatsheets, blogs, hacks, one-liners, cli/web tools and more.
-
Awesome Database Learning: a list of learning materials to understand database internals.
-
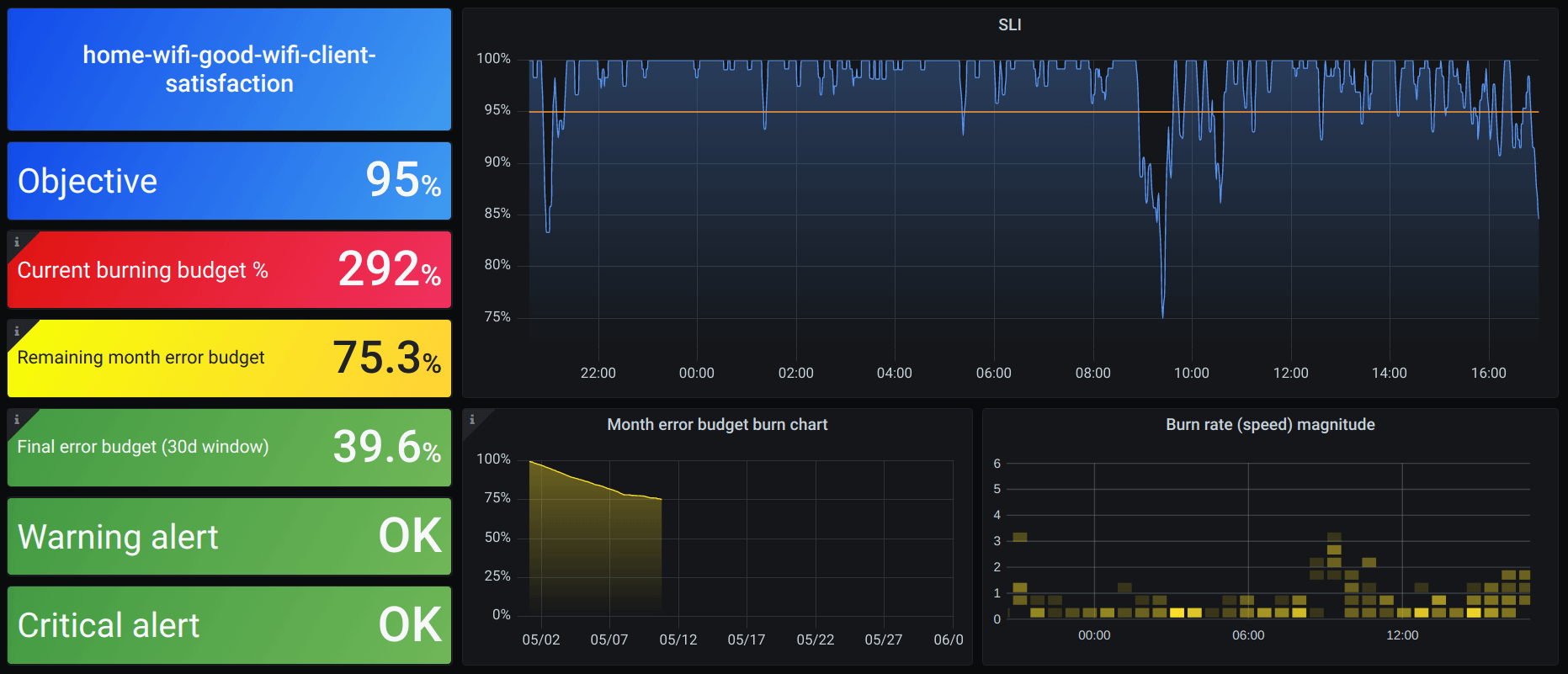
Sloth: easy and simple Prometheus SLO (service level objectives) generator.
-
Toward Vagrant 3.0: in order to support its growing ecosystem and community as we move toward the 3.0 release, we are making changes to Vagrant that will maintain its Ruby-based features while being ported to Go.
-
Ness: deploy web sites and apps to your own cloud account effortlessly.
-
StarQueue: a free hosted HTTP message queue.
☸️ Kubernetes
-
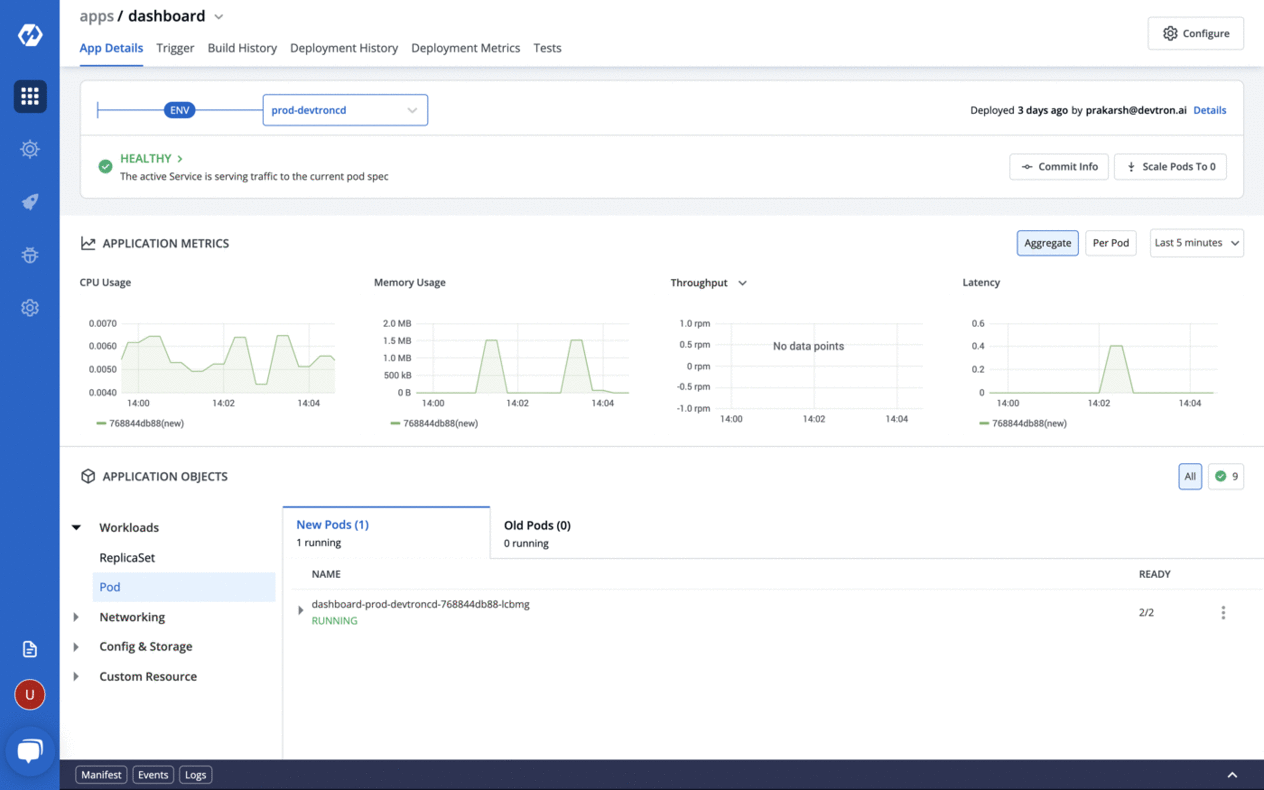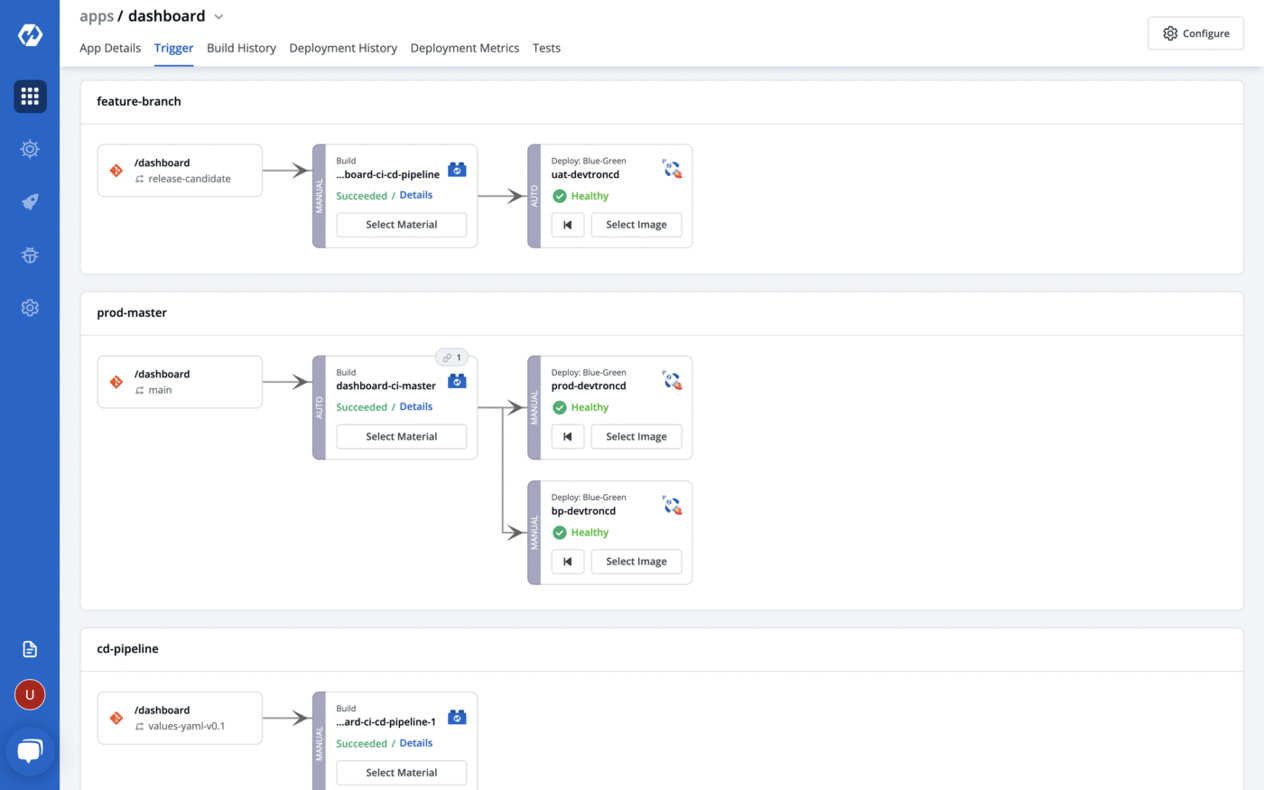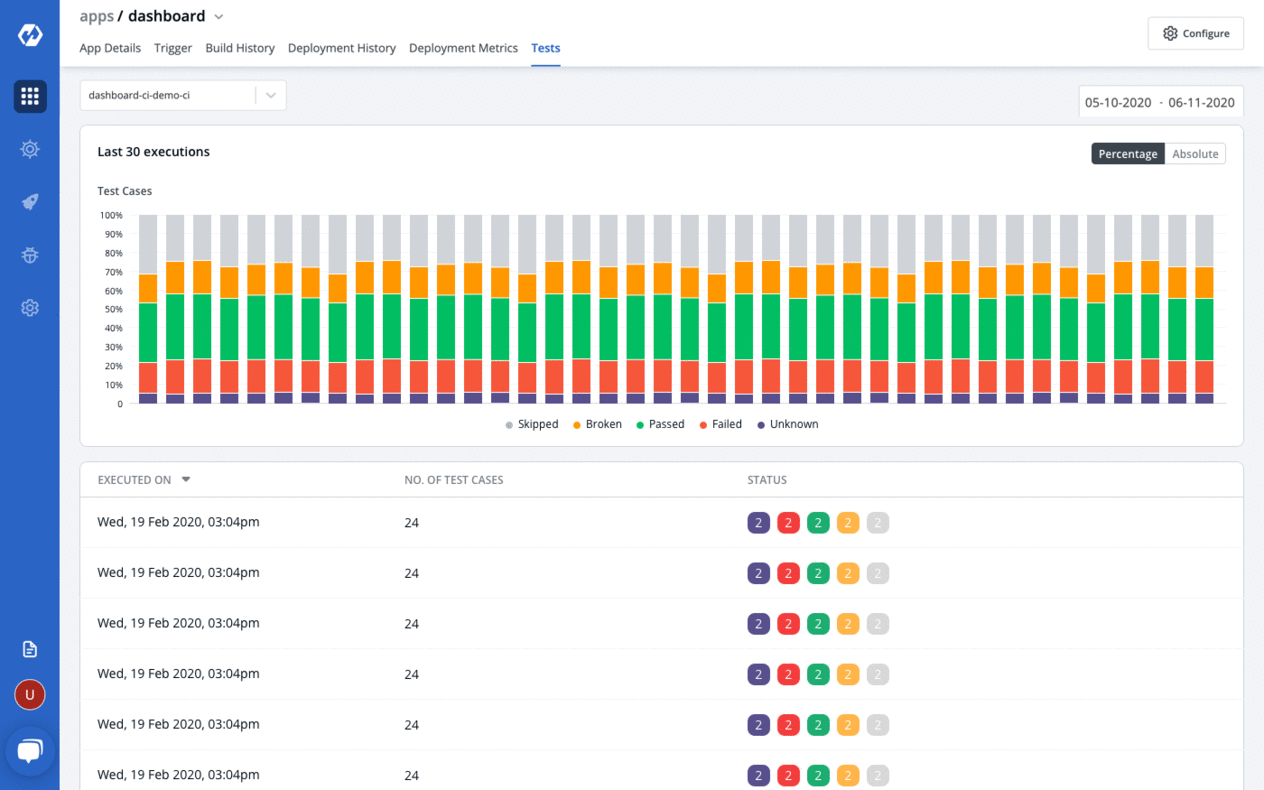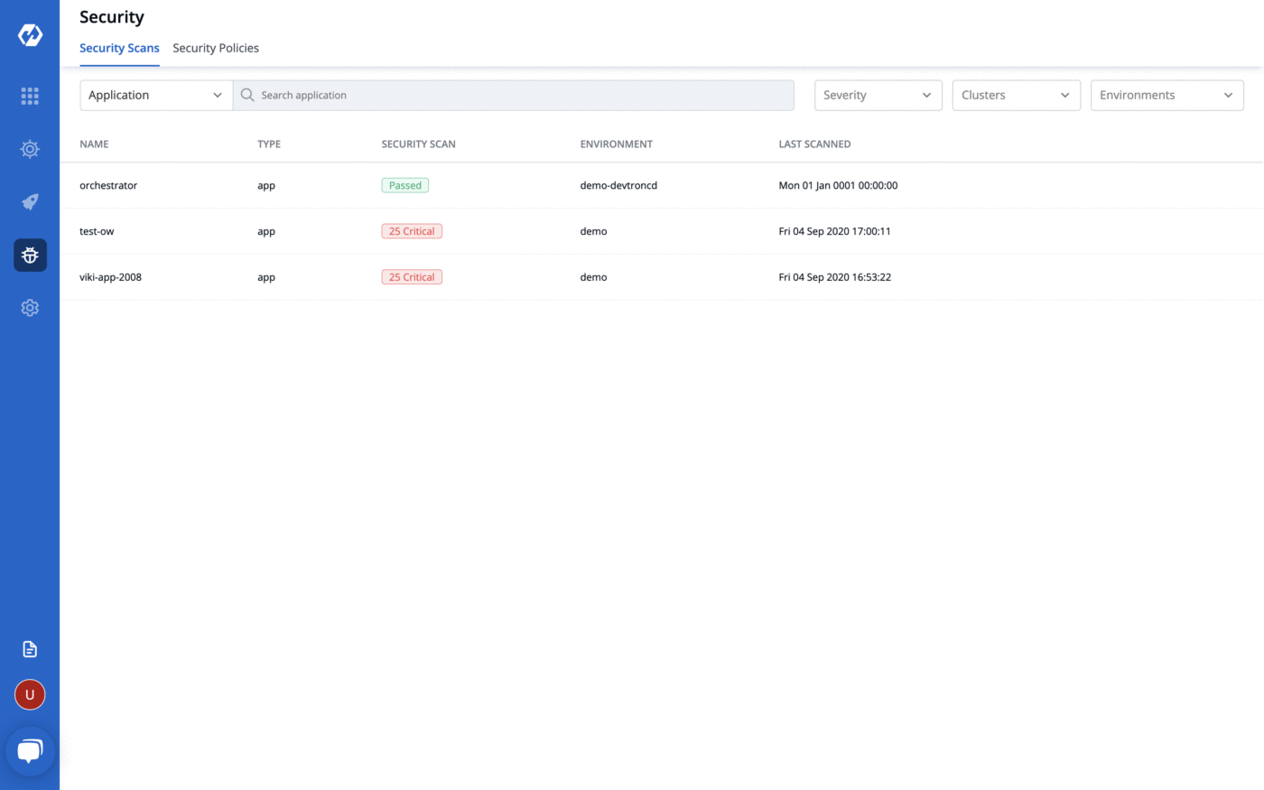
Devtron: an open source software delivery workflow for Kubernetes written in Go.
-
13 Best Practices for using Helm: Helm is an indispensable tool for deploying applications to Kubernetes clusters. But it is only by following best practices that you’ll truly reap the benefits of Helm. Here are 13 best practices to help you create, operate, and upgrade applications using Helm.

- Kubernetes Learning Path: “since Kubernetes is growing very rapidly, online tutorials, books are getting easily outdated, but most of the information is available on the official website. So I have made an effort to collate all the important topics with links that provide the learning path for Beginners to get started with Kubernetes.”
🔐 Security
-
New DNS Name Server Hijack Attack: researchers found a “novel” class of DNS vulnerabilities in AWS Route53 and other DNS-as-a-service offerings that leak sensitive information on corporate and government customers, with one simple registration step.

-
MyBook Users Urged to Unplug Devices from Internet: malicious hackers are remotely wiping the drives using a critical flaw that can be triggered by anyone who knows the Internet address of an affected device
-
How a Docker footgun led to a vandal deleting NewsBlur’s MongoDB database
-
DevSecOps: Why Security Shouldn’t be Sacrificed for Speed: the road to DevSecOps is neither quick nor easy. By tackling the necessary cultural and technical challenges now, organizations will end up in a far better place as they look to build digital success on safer and less risky foundations.

- FBI sold phones to organized crime and read 27 million “encrypted” messages: messages were routed to an FBI-owned server and decrypted with a master key.
💻 Programming
-
Understanding thread stack sizes and how Alpine is different
-
Python Fire: a library for automatically generating command line interfaces (CLIs) from absolutely any Python object.

- The Cost of 100% Reliability: the more reliability you want, the more it costs, with a rule of thumb that each additional 9 of reliability (eg. moving from 99% to 99.9% reliability) costs 10 times more to achieve. But what contributes to that cost increase?
🐧 Linux
-
Modern Unix: a collection of modern/faster/saner alternatives to common unix commands.
-
Vim vs. Nano vs. Emacs: Three sysadmins weigh in: three editors. Three experts. Which Linux text editor is right for you?
🚢 Leadership
-
How Lowe’s meets customer demand with Google SRE practices: “today we hear from the Lowe’s SRE team. They share about how they have been able to increase the number of releases they can support by adopting Google’s Site Reliability Engineering (SRE) framework and leveraging their partnership with Google Cloud.”
-
Are we there yet? Thoughts on assessing an SRE team’s maturity
☁️ Cloud
-
Seven guiding principles of serverless systems: the big question in serverless design is how do you know your team is doing it correctly? Serverless can feel fuzzy, and best practices don’t feel so obvious. The good news is that there are some fundamental principles that can help you navigate your journey.
-
Navigating the 8 fallacies of distributed computing: the fallacies of distributed computing are a list of 8 statements describing false assumptions that architects and developers involved with distributed systems might make (but should undoubtedly steer away from). In this blog post, we’ll look at what these fallacies are, how they came to be, and how to navigate them in order to engineer dependable distributed systems.
AWS
-
Introducing a Public Registry for AWS CloudFormation: a new searchable collection of extensions that allows you to discover, provision, and manage third-party extensions, which include resource types (provisioning logic) and modules published by AWS’s Partner Network.
-
AWS Client VPN launches desktop client for Linux: the Linux Desktop client has feature parity with the existing Windows and macOS Desktop clients.
-
CloudWatch adds 14 new Metric math functions: including
RUNNING_SUM,TIME_SERIES, andDATAPOINT_COUNT. Two newFILLvariants, two logarithmic functions, two functions for calculating the difference between each datapoint, and five time functions are also now supported.
-
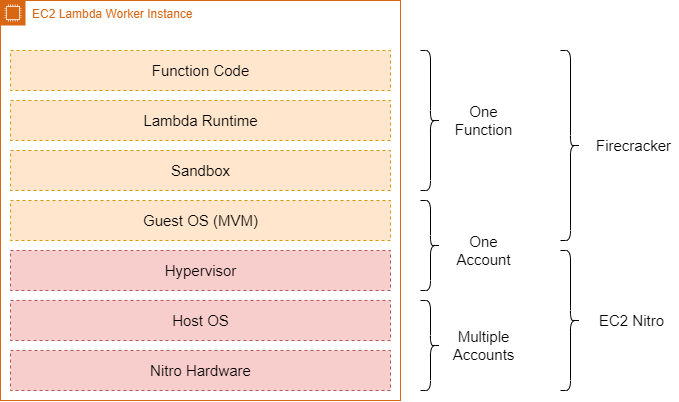
Behind the scenes, AWS Lambda: What’s better than containerization? Written in Rust, open source and the core of how AWS Lambda functions are powered, Firecracker!
-
Amazon EC2 Inf1 instances: new features, improved performance and lower prices.
-
Increase Amazon Elasticsearch Service performance by upgrading to Graviton2
Article version: 1.0.0